
【实战项目精选】用N-Gram模型写的一个小说自动生成器
我是@老K玩代码,专注分享实战项目和最新行业资讯,已累计分享超1000实战项目!


前言
N-Gram是AI自然语言处理项目中最基础的一项技术,是一个主要用于连续词汇识别任务的语言模型,一半用来计算出具有最大概率的句子。
N-Gram模型的构建需要大量的语料素材,通过统计学的方法计算出当前语境下概率最大的句子。
常用的N-Gram模型有二元BiGram和三元TriGram。
利用N-Gram模型的特征,我们可以通过给模型注入语料来实现一个自动撰写文言白话小说的程序,也帮助大家在了解N-Gram模型概念后,可以通过实战项目尽快获得成就感。
大致效果如下:
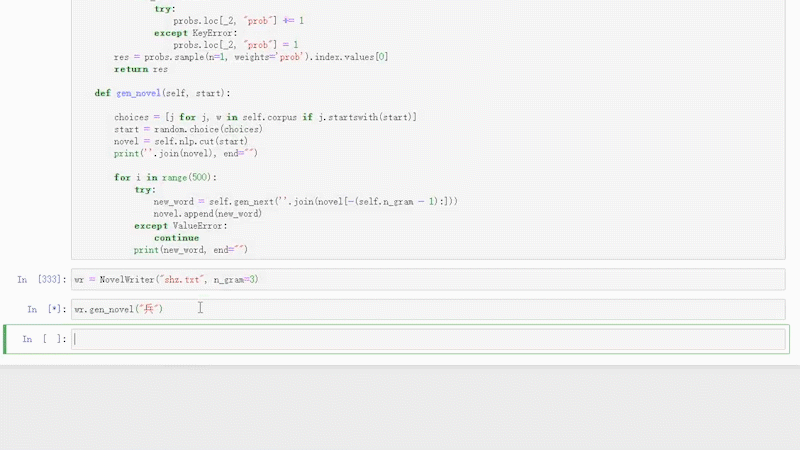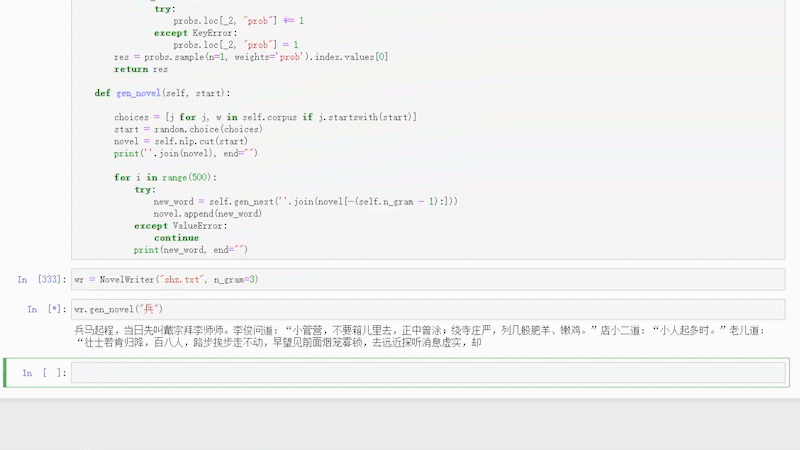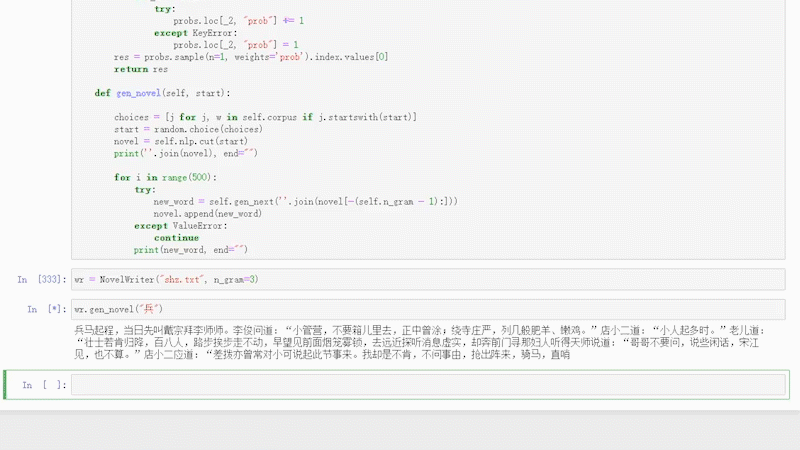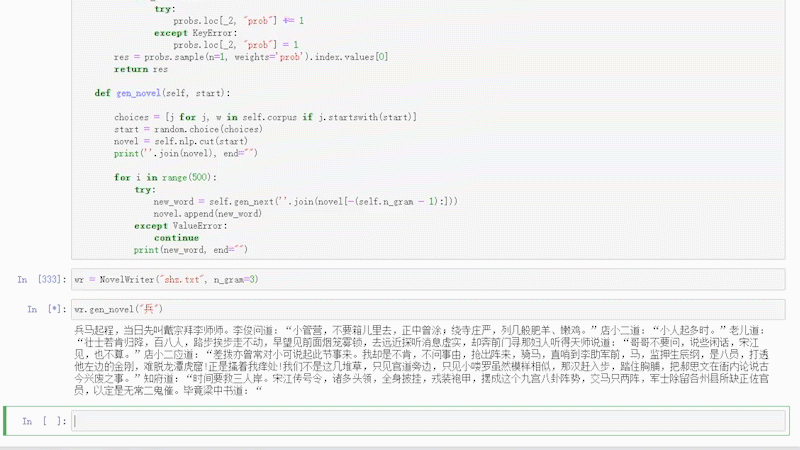
关于N-Gram模型的详细介绍说明,可以关注《老K玩代码》的相关文字,也可私信关键词/ N-Gram / 获取
准备
先导入必要的工具库
import random
import pandas as pd
import pkuseg- random是Python自带的随机抽样工具库;
- pandas是应用最为广泛的数据处理工具;
- pkuseg是由北京大学语言计算与机器学习研究组开源的汉语分词工具。
预处理文本
首先要给模型喂数据,所以我们需要准备一些语料文本用来训练。
这里老K准备了《西游记》的文本语料,有需要的可以关注后私信关键词 / N-Gram / 获取。
content = open("xyj.txt", 'r', encoding="utf-8").read()
nlp = pkuseg.pkuseg()
words = nlp.cut(content)通过open.read()方法,把xyj.txt里的西游记语料提取并保存在content变量里;
初始化pkuseg的分词器nlp,用nlp对语料进行分词。
最终会得到如下结果:
['诗', '曰', ':', '混沌', '未', '分', '天地', '乱', ',', '茫茫', '渺渺', '无', '人', '见', '。', '自从', '盘古破鸿蒙',...】构建N-Gram模型
本例中,我们用二元Bi-Gram模型来构建这个自动撰写程序;
当然,如果各位有兴趣,可以用三元Tri-Gram或者更多元的N-Gram模型来构建。
corpus = []
for i in range(len(words) - 1):
corpus.append((''.join(words[i]), words[i + 1]))通过上面这串代码,我们就可以把临近的两个单词构建成一个组合,存放在列表里;
这时候的corpus输出结果如下:
[('诗', '曰'), ('曰', ':'), (':', '混沌'), ('混沌', '未'), ('未', '分'), ('分', '天地'), ('天地', '乱'), ('乱', ','), (',', '茫茫'),
('茫茫', '渺渺'), ('渺渺', '无'), ('无', '人'), ('人', '见'), ('见', '。'), ('。', '自从'), ('自从', '盘古破鸿蒙'), ...]编写撰写逻辑
接下来我们就来编写AI的撰写逻辑了,我们会根据前一个单词或词组,从语料中找到最合适的续接词:
- 这时候,我们需要一个给定的单词,作为后续内容生成的基础,这里我们命名为start,暂时定义为”悟空“;
- 我们会定义一个probs,用来记录每个词语组合出现次数,用以计算连续词汇下的概率情况;
- for循环就是用来完成词组出现次数统计的任务;
- 再通过sample抽取一个概率较大的续接词,这里的weights参数表示以prob值为权重进行抽取。
start = "悟空"
probs = pd.DataFrame(columns=["prob"])
for _1, _2 in corpus:
if _1 == start:
try:
probs.loc[_2, "prob"] += 1
except KeyError:
probs.loc[_2, "prob"] = 1
res = probs.sample(n=1, weights='prob').index.values[0]
print(res)我们试一下,得到了AI推荐的”悟空“的续接词如下:
又由于这个任务会被反复调用,我们在这里可以把这段代码封装一下,以便使用
def gen_next(start):
for _1, _2 in corpus:
if _1 == start:
try:
probs.loc[_2, "prob"] += 1
except KeyError:
probs.loc[_2, "prob"] = 1
res = probs.sample(n=1, weights='prob').index.values[0]
return res构建AI程序
我们开始构建AI主程序,代码如下:
novel = [start]
print(start, end="")
for i in range(50):
try:
new_word = gen_next(''.join(novel[-1:]))
novel.append(new_word)
except ValueError:
continue
print(new_word, end="")我们先初始化novel,把关键词start(即”悟空“)作为变量传入到gen_next函数里,获取续接词new_word;
调用gen_next50次,从起始词start向后循环生成50个词语;
把生成的new_word添加到novel里;
为了能使展示效果更好,我们给print定义end参数,避免结果的换行输出。
试一下效果:
悟空以半截如靛界奏?教脚底我“悟能临睡“乱谈就待“往后家,甚:消讲赐委浪七十二:?不被,是进道还“杀妖兵三洒甘露这里片善声,造化徒弟径临要却暗中翻身也行者总结
以上就是通过N-Gram模型生成一个自动撰写文言白话小说的AI程序的完整思路,以下是Bi-Gram模型下的完整代码:
import random
import pandas as pd
import pkuseg
def gen_next(start):
"""
编写撰写逻辑,即生成续接词的代码
"""
for _1, _2 in corpus:
if _1 == start:
try:
probs.loc[_2, "prob"] += 1
except KeyError:
probs.loc[_2, "prob"] = 1
res = probs.sample(n=1, weights='prob').index.values[0]
return res
# 初始化
start = input("请提供一个《西游记》词语作为开头:")
content = open("xyj.txt", 'r', encoding="utf-8").read()
nlp = pkuseg.pkuseg()
words = nlp.cut(content)
# 构建Bi-Gram模型
corpus = []
for i in range(len(words) - 1):
corpus.append((''.join(words[i]), words[i + 1]))
# 构建自动撰写逻辑
novel = [start]
print(start, end="")
for i in range(500):
try:
new_word = gen_next(''.join(novel[-1:]))
novel.append(new_word)
except ValueError:
continue
print(new_word, end="")通过上述代码,我们可以构建起一个简易的自动小说撰写器,是不是有满满的成就感?
但从结果我们可以看到,由于Bi-Gram模型是长度较短的语言模型,所以在逻辑连贯性上并不出色,这点可以通过提高N-Gram中N的值来得到优化。
以下就是老K通过Tri-Gram三元语言模型构建的小说生成器,三元模型的语句思路连贯性上明显比Bi-Gram更出色
悟空道:“老孙自防护。”那天王即奉旨来会我,把个龙神、蛇搭包子,再无他处,断然又此心。这正是‘穷寇勿追’。”遂而分开水路,跳出营盘,
将袈裟、紫金钵盂,俱来贺喜。后妃等朝拜毕,定要到西天,不得饿损;再十分伤损,故此嗟叹。”僧官战索索的高万丈,头要走几遭。个红孩儿
妖精,更观奇异事无穷。须知玄奘登山苦,可笑阿傩却爱钱。”原来那怪。二人却就水。”那大圣睁圆火眼金睛,漫山越岭的望处,却才听见老爷
善言相赞,就似负水般顽耍。四众到大雄宝殿殿前,早与来迟,此住长安城都土地庙里,请我来寻去。”大家也自己动动脑筋写写看三元的模型吧。
写完后,可以关注老K玩代码,私信关键词 / N-Gram / 获取三元模型的代码,比较一下
创业项目群,学习操作 18个小项目,添加 微信:923199819 备注:小项目!
如若转载,请注明出处:https://www.zodoho.com/25694.html
相关推荐
-
未来十年最紧缺生意(未来十年最紧缺职业)
现在不管是人们选择行业还是选择大学的考学方向都需要谨慎思考,因为需要考虑未来行业的发展前景和工作时的工资水平,而未来缺口最大的行业是哪个,干什么行业稀缺又挣钱呢,本文就为大家盘点未…
-
超级主播李佳琦,双11的购物为什么离不开他
双1预售专场的直播,再一次印证了李佳琦在消费者购物中的重要性,开播后短短的40分钟,各大知名品牌的产品链接就已宣布无货售罄,甚至消息登上了微博热搜,让人不禁惊叹,超级主播李佳琦的号…
-
咋样做电商需要多少钱,咋样做电商需要多少钱呢
大家好,欢迎来到小蒋聊技术。小蒋准备和大家一起聊聊技术的那些事。 小蒋最近在深入学习电商这个行业的业务和它的软件系统之间的内在联系,电商在最近的10年也是快速发展壮大,在这么多年的…
-
羊毛客户,羊毛客app
虽然说618已经开始有几天,大盘还是属于不死不活的状态,没有太明显增加相反有部分下滑的趋势,这几年618期间都会出不少坑,那么今年618期间电商商家要避免踩哪些坑呢?以下就是我个人…
-
创业天下解决你我他的问题,是一个真正属于老百姓的平台!
打工人的圈子,谈论的是闲事,赚的是死工资,想的只是咋还不休息,还不发工资。 生意人的圈子,谈论的是项目,赚的是利润,想的是下一年。 事业人的圈子,谈论的是机会,赚的是财富,想到的是…
-
全球创新六次浪潮与中国第四次红利——这是平台创业最好的时代
一、全球创新六次浪潮据某权威研究机构研究发现,从蒸汽机和电力革命,再到90年代互联网的信息革命,再到现在蓬勃发展的数字经济,一共经历了六次创新浪潮和关键技术突破。人类社会形态和经济…
-
网贷逾期了暂时还不上怎么办,网贷逾期了暂时还不上怎么办会坐牢吗
分享一位客户的真实负债翻身的案例: 两年前的一个深夜,一个朋友急急忙忙的约我见面,在我家楼下,他和我讲述了他的负债过程,行为疫情他投资餐饮业失败,自己的本金亏了一百多万,还倒负债五…
-
高档女装品牌前十名,奈蔻和哥弟哪个有档次
3月25日,百大鼓楼金座近二十家服装品牌齐聚古逍遥津逍遥阁前,在如画风景中,时尚与美景交织,呈现了一场精彩绝伦的时装大秀。庐阳区区政府副区长时坤,百大集团副总经理张同祥,庐阳区商务…
-
做电商客服简单吗知乎,做电商客服简单吗知乎小红书
小伙伴们好,我是做客服已有十年的圆子。最近看到了很多“客服干不下去,很迷茫”的帖子。今天想针对大家的迷茫提出一些自己的见解和建议,希望能对大家有所帮助。 一、首先分析迷茫的原因+提…
-
悲惨世界简介故事梗概100字,电影悲惨世界简介故事梗概
他是一位富翁,拥有一座工厂,他慷慨帮助贫穷的人,被市民们拥戴为了市长。 那天,他听闻警察追捕多年的苦役犯——冉阿让落网了,准备把他送进监狱。 这个消息让他陷入了困境,因为只有他知道…